

 For today’s litigation technology tip, I have a quick way to strip out unwanted hard returns from the text of Acrobat documents.
For today’s litigation technology tip, I have a quick way to strip out unwanted hard returns from the text of Acrobat documents.
Litigators often need to copy text from the image of one document (e.g., from an opponent’s discovery response) and paste it into another document (e.g., a discovery motion). Unfortunately, copying text from a scanned Acrobat PDF will often copy unwanted hard returns. These hard returns mess with the formatting of your destination document.
To solve this problem, I take the following steps:
- Open a blank Microsoft Word document;
- Highlight and copy the text from the Adobe document;
- Paste the copied text into Microsoft Word (I like to paste the text without formatting to avoid any other junk such as fonts that might have been in the Adobe document);
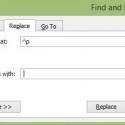
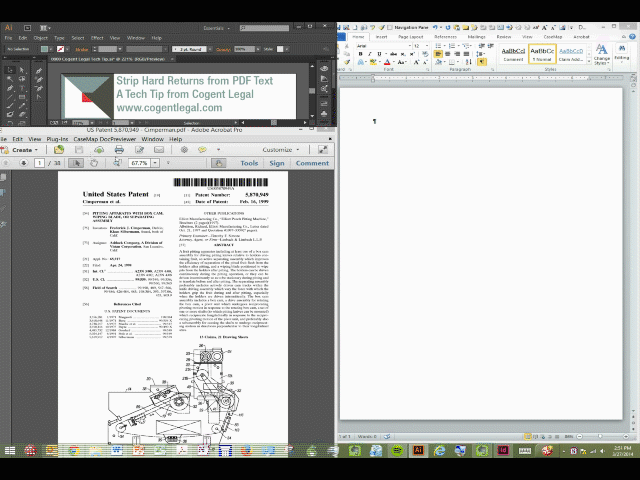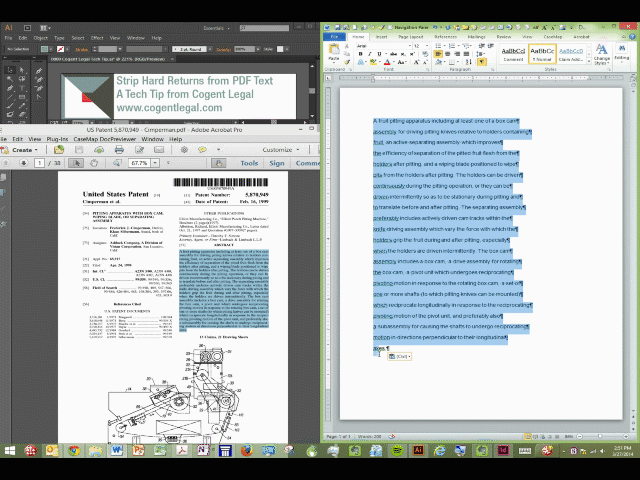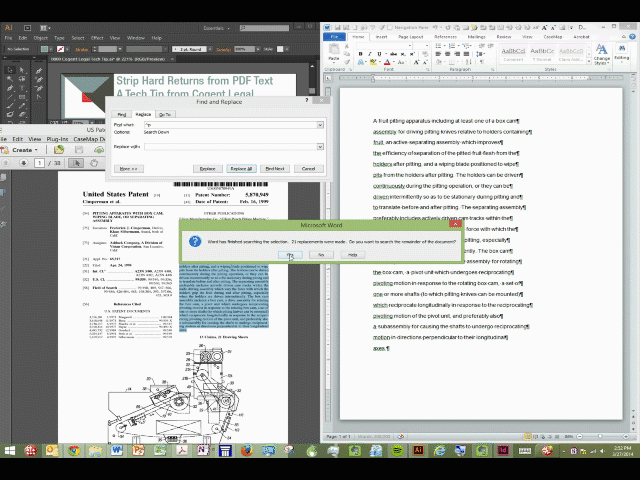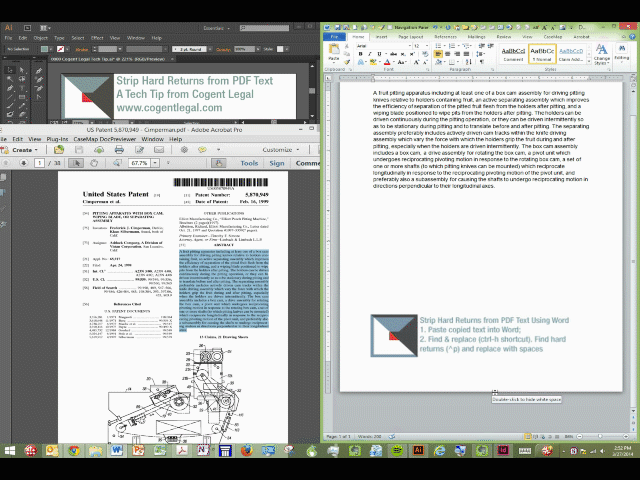
- Use Word’s Find and Replace command (Ctrl-H is the Windows shortcut) to search for hard returns (^p is the code for a hard return that you need to search for);
- Put ^p in the Find box and a space in the Replace box, and choose “Replace All.” Presto! The hard returns vanish.
- Copy the newly cleaned up text and paste it into the destination document.
Check out the animated GIF I made below to see the steps.
I hope that this tip saves you some time. Email me (michael.kelleher@cogentlegal.com) or give me a call at 510-350-7616 if you have questions about this or any other aspect of litigation technology.
To receive updates from this blog, please click to subscribe by email.